Updating a live OpenStack cloud
jistr, marios, gfidente
Talk Overview
- Deployment structure recap
- Major version upgrades vs. minor version updates
- Updates in TripleO
- What could possibly go wrong?!
- Demo video
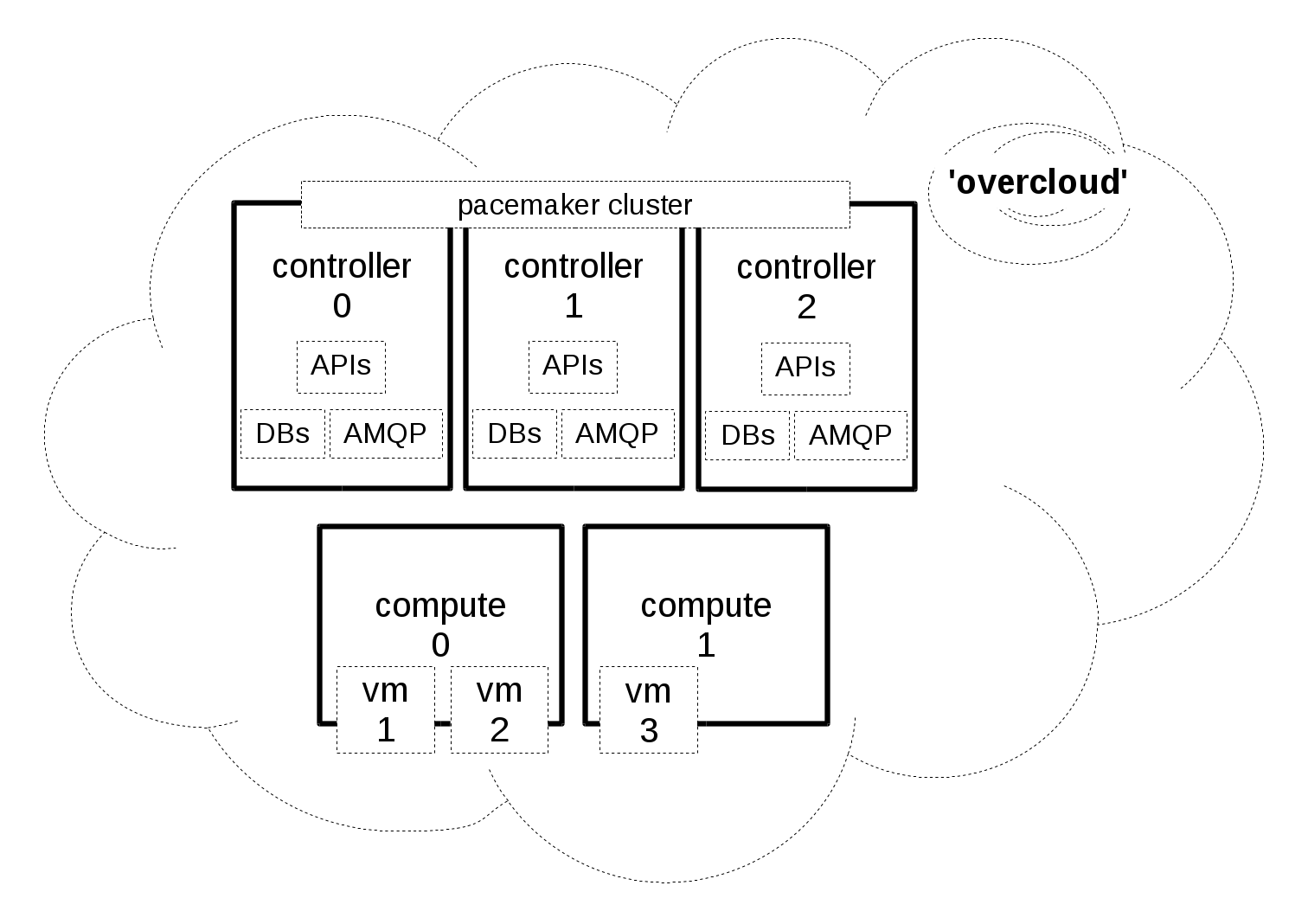
Deployment Structure
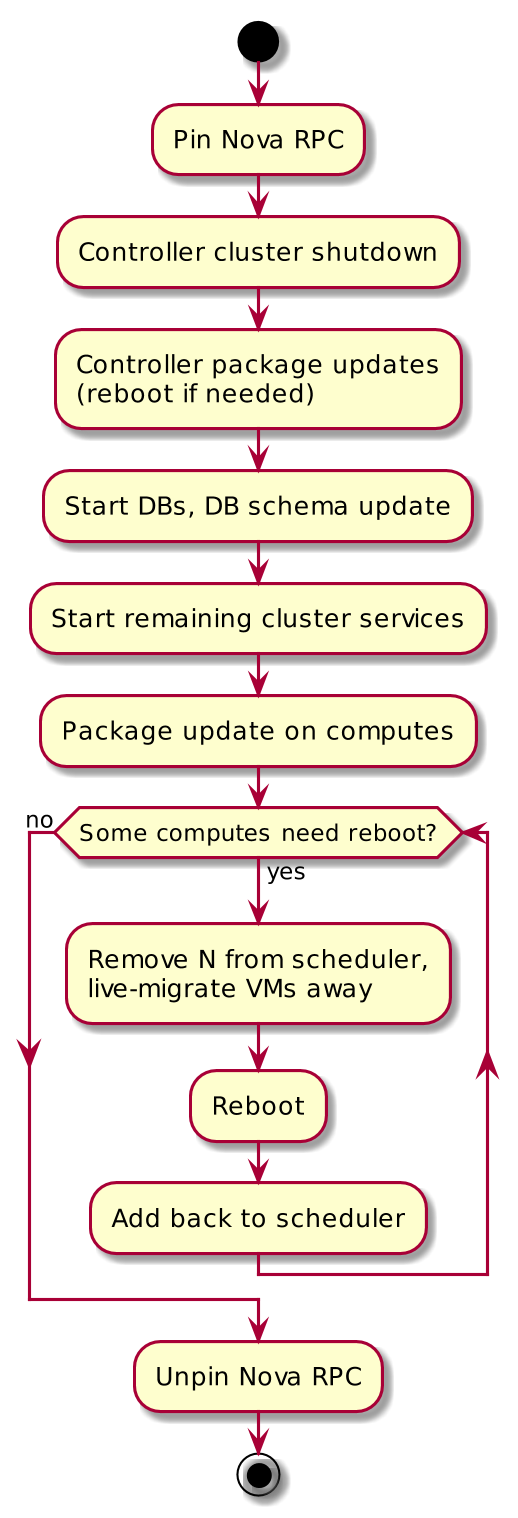
Upgrades (major version)
- DB schemas and AMQP messaging (RPC) can change
- Upgrade controllers in parallel
- DB schema must match service expectations
- Cloud management downtime
- Upgrade computes serially (in batches)
- No direct DB connection, RPC pinning
- Service-by-service upgrade is a possibility too
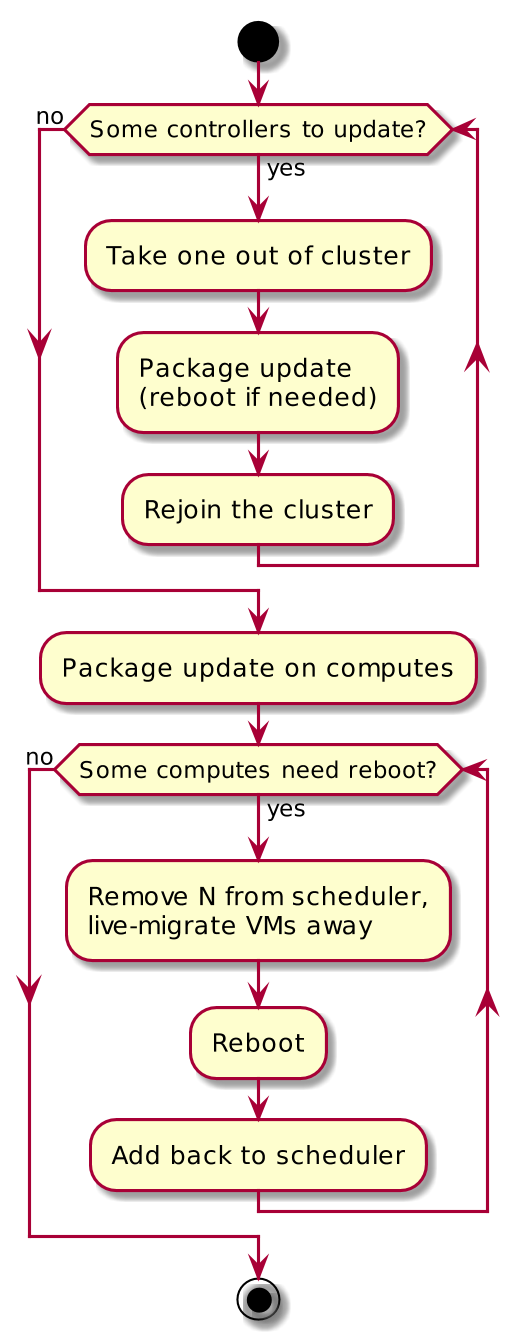
Updates (minor version)
- DB schemas do not change, AMQP messaging does not change or is backwards compatible
- Challenge is in uptime expectations
- Rolling updates on the controllers (node-by-node)
- Some services rely on Pacemaker for proper leaving/rejoining the cluster
- “Normal” package update on the computes
The Setup
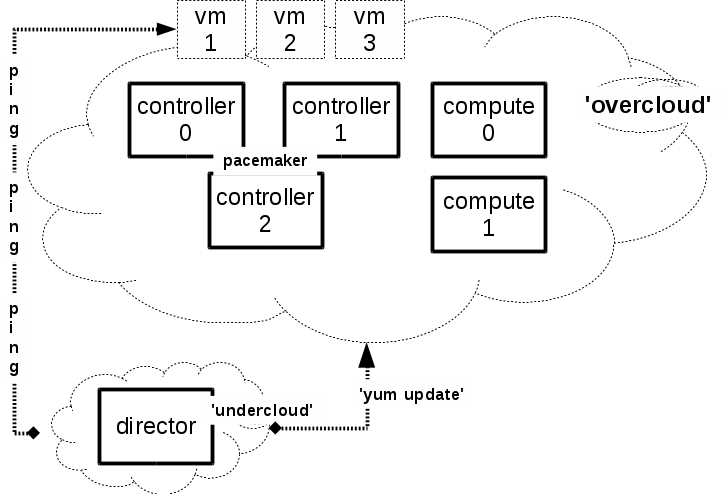
Start Update
- From the Manager node
openstack overcloud update stack overcloud -i --templates -e overcloud-resource-registry-puppet.yaml -e …
- Sets pre-update hook on each node – heat native feature.
- Also sets the UpdateIdentifier. Need the update to proceed one node at a time.
Compute Node
- Simplest case (no pacemaker, less services - nova-compute, agents)
- Update the openstack puppet modules
Controller Node
- On one controller at a time, (breakpoints mainly for this).
- Matching pre/post update environments (example the neutron pacemaker constraints).
- Stop the cluster on that controller, maintenance mode
- Yum update
- Rejoin the cluster
yum_update.sh
- This is delivered as the config property for a SoftwareDeployment (Heat).
- Checks the update_identifier first
- echo "Not running due to unset update_identifier"
- Contains the update logic, pacemaker, yum update
What could possibly go wrong?!
Nothing, in four different ways!
- Tooling Bugs (Heat network_id/network mapping)
- Workflow Bugs (Pacemaker constraints)
- Subtle Bugs (Neutron L3 HA)
- Evil Bugs (UpdateIdentifier)
What could possibly go wrong?!
We don't want a new network, we're just calling it (by) name
network_id <-> network (name) mapping
Heat developers helped, we had to backport the fix into the stable branch
https://bugzilla.redhat.com/show_bug.cgi?id=1291845
(Tooling)
What could possibly go wrong?!
How come Pacemaker is failing to failover the services?
Services fail to stop
HA people helped, we needed to fix the constraints to shutdown cleanly!
(Workflow)
What could possibly go wrong?!
Why is that IP still on the node we supposedly killed?
Neutron agents were down but keepalived was still running
Neutron developers helped, newer version wasn't affected
https://bugzilla.redhat.com/show_bug.cgi?id=1175251
(Subtle)
What could possibly go wrong?!
UPDATE_COMPLETE, scaling fails though!
Luckily there is people testing this all
https://bugzilla.redhat.com/show_bug.cgi?id=1290572
(Evil)
Demo Video
Help us making it better
- Puppet modules distributed via the Undercloud
- Update steps bounded to the services
- Pacemaker resource provider for puppet?
- More?